java线程池

今天作为复习,在此扯一扯java线程池的相关概念,并分享一个生产因为线程池使用不当而导致的重大事故。
基本概念
线程池,顾名思义里面是一个存放着线程的容器,可以反复利用其中的线程处理实现了对应的Runnable的类。从而避免了反复创建,销毁线程的开销。
构造函数讲解
以下为线程池构造方法的源码
/**
* Creates a new {@code ThreadPoolExecutor} with the given initial
* parameters.
*
* @param corePoolSize the number of threads to keep in the pool, even
* if they are idle, unless {@code allowCoreThreadTimeOut} is set
* @param maximumPoolSize the maximum number of threads to allow in the
* pool
* @param keepAliveTime when the number of threads is greater than
* the core, this is the maximum time that excess idle threads
* will wait for new tasks before terminating.
* @param unit the time unit for the {@code keepAliveTime} argument
* @param workQueue the queue to use for holding tasks before they are
* executed. This queue will hold only the {@code Runnable}
* tasks submitted by the {@code execute} method.
* @param threadFactory the factory to use when the executor
* creates a new thread
* @param handler the handler to use when execution is blocked
* because the thread bounds and queue capacities are reached
* @throws IllegalArgumentException if one of the following holds:<br>
* {@code corePoolSize < 0}<br>
* {@code keepAliveTime < 0}<br>
* {@code maximumPoolSize <= 0}<br>
* {@code maximumPoolSize < corePoolSize}
* @throws NullPointerException if {@code workQueue}
* or {@code threadFactory} or {@code handler} is null
*/
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
以上便是java线程池中的最核心的构造方法。现在来讲解其每个参数的意义
- corePoolSize核心线程数,如果线程池中的线程数小于核心线程数当有新的任务需要执行是就会创建一个对象,当线程数量到达核心数,则将新来的任务加入队列中
- maximumPoolSize 最大线程数,当线程数量大于等于核心线程数量,且放置任务的workQueue已满时则会继续新增线程,直至达到maximumPoolSize
- keepAliveTime,unit 这2个参数是配合使用的,当线程数量大于核心线程数量时,如果其中的线程有keepAliveTime+unit的时间是空闲的则会干掉改线程
- workQueue 用于存放任务的阻塞队列,当核心线程数达到最大时,如果新进来了任务则会加入到这个阻塞队列
- threadFactory,用于生产线程的工厂,你可以自定义一个工厂,线程名字自定义
- RejectedExecutionHandler 任务的拒绝策略,当线程数到达最大且阻塞队列也满了的时候就会采用这个策略对新进来的任务进行出来,上次生产事故,就是 由于拒绝策略不当而导致
任务调度流程
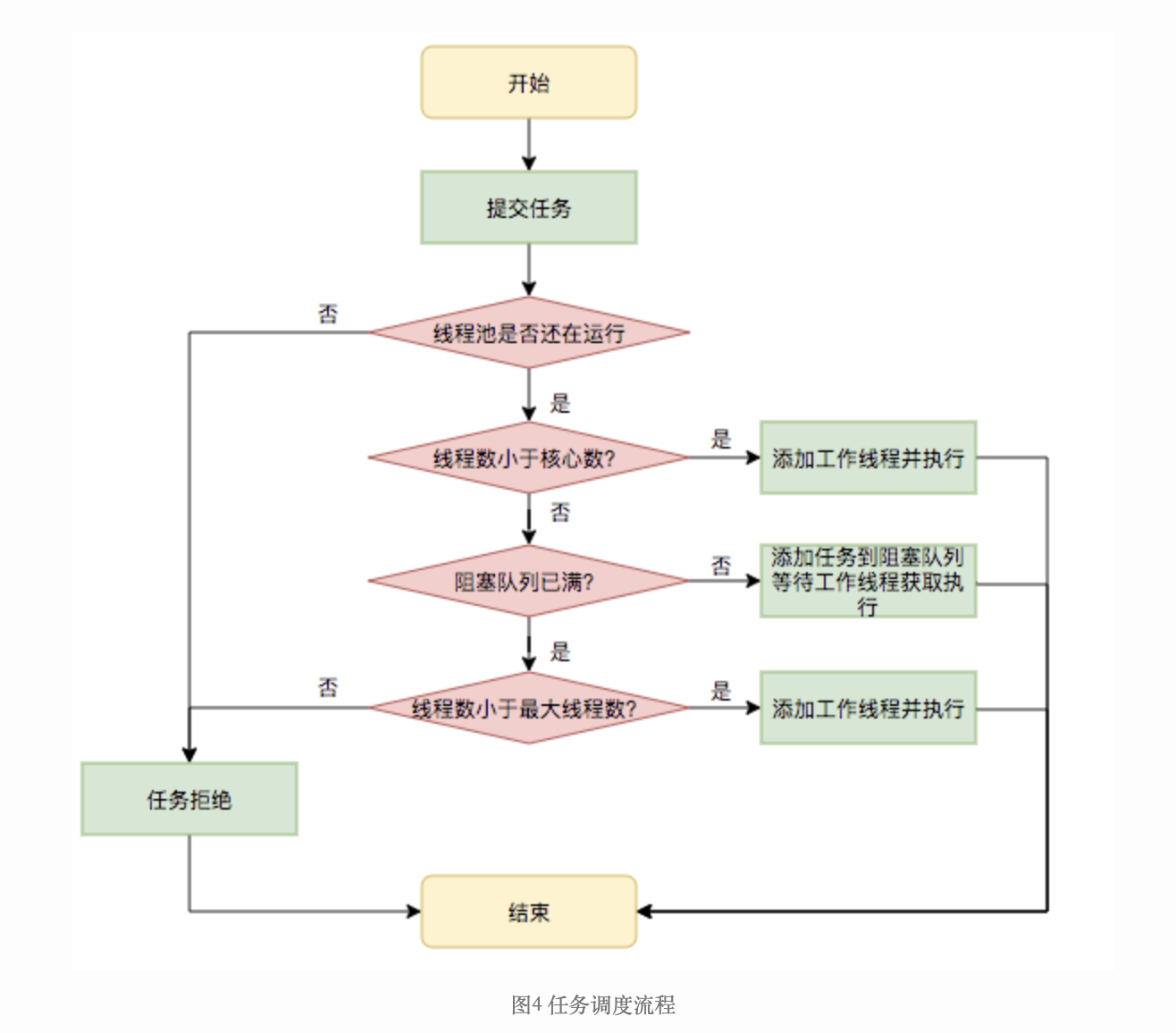
结合上图与构造函数,我相信这个主要流程你已经清楚了
数据结构
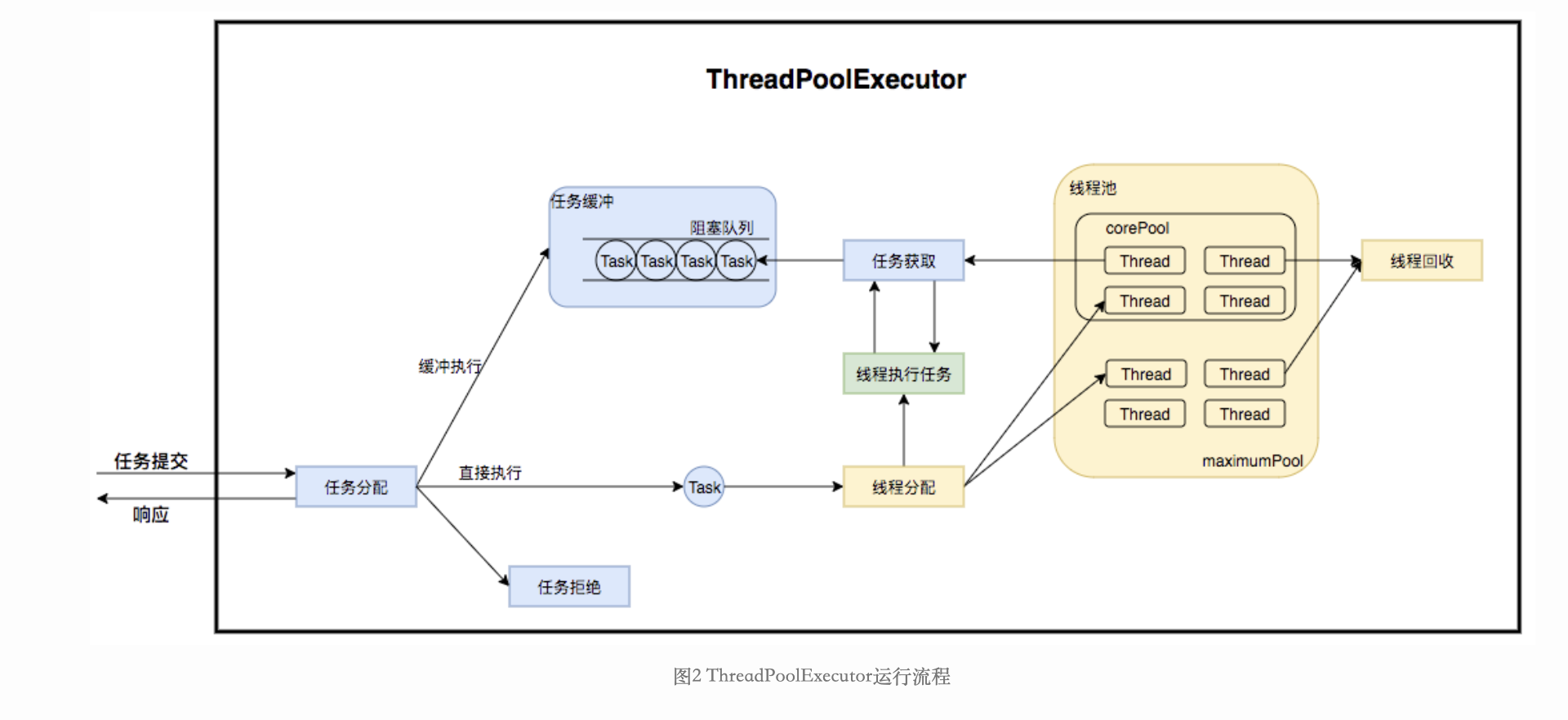
线程池在内部实际上构建了一个生产者消费者模型,将线程和任务两者解耦,并不直接关联,从而良好的缓冲任务,复用线程。线程池的运行主要分成两部分:任务管理、线程管理。任务管理部分充当生产者的角色,当任务提交后,线程池会判断该任务后续的流转:
(1)直接申请线程执行该任务;
(2)缓冲到队列中等待线程执行;
(3)拒绝该任务。线程管理部分是消费者,它们被统一维护在线程池内,根据任务请求进行线程的分配,当线程执行完任务后则会继续获取新的任务去执行,最终当线程获取不到任务的时候,线程就会被回收。
其提供的创建线程池的几种方法
jdk默认提供的方法不好意思都不建议使用在此在说一说他们缺点
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
由构造函数可以看出,他的队列无限大,会引发oom
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
线程数太大也会oom
拒绝策略
可以自定义拒绝策略实现RejectedExecutionHandler即可,在此主要说一说jdk自带的拒绝方法
- DiscardPolicy(丢弃策略),直接丢弃
- DiscardOldestPolicy(弃老策略),丢弃队列中最靠前的,随后将新任务加入其中
- AbortPolicy(拒绝并抛出异常)
- CallerRunsPolicy,此方法由调用者线程进行执行,通常只有很重要的方法才会使用这个
生产中线程池使用不当
场景
支付事业部生产环境,突然所有访问超时,机器中一个节点处理不了任何请求,而且对应mysql的机器访问全部超时。瘫痪长达半个小时
排查
每个人员排查自己所负责的组件发现,kafka假死。为何kafka假死会出现这么严重的问题。
排查代码发现代码逻辑大概如下,由于监控需求需要把一些数据发入kafka。于是工作人员在写入数据库之后的事务中,使用了异步线程池,异步的将监控数据加入kafka,异步线程池中所使用的策略为CallerRunsPolicy。
原因分析
- 对于不重要的业务,不建议使用分布式事务
- 此场景中,线程池的策略为CallerRunsPolicy,当kafka阻塞时,线程池拉满,由调用线程来执行,导致tomcat中线程拉满,此节点接受不了任何请求了
- 分布式事务中,开始了mysql的事务但是kafka一直阻塞,导致mysql连接与资源一直被占用且拉满。于是长事务导致mysql资源基本耗尽
最后奉上美团的分享
https://tech.meituan.com/2020/04/02/java-pooling-pratice-in-meituan.html