zero-copy and mmap

本文要讲的是零拷贝(zero-copy)与内存映射(mmap)
要讲这2个跟底层挂钩的东西,首先要了解,用户态,内核态,他们之间的切换
了解了用户态内核态后,我们用一次普通io与zero-copy,mmap进行性能的比较,像redis用到的epoll,ngnix,kafaka里面都有涉及到mmap或者zero-copy
用户态与内核态
内核态:cpu可以访问内存的所有数据,包括外围设备,例如硬盘,网卡,cpu也可以将自己从一个程序切换到另一个程序。
用户态:只能受限的访问内存,且不允许访问外围设备,占用cpu的能力被剥夺,cpu资源可以被其他程序获取。
为什么要有用户态和内核态?
由于需要限制不同的程序之间的访问能力, 防止他们获取别的程序的内存数据, 或者获取外围设备的数据, 并发送到网络, CPU划分出两个权限等级 -- 用户态和内核态。
用户态与内核态切换
所有用户程序都是运行在用户态的, 但是有时候程序确实需要做一些内核态的事情, 例如从硬盘读取数据, 或者从键盘获取输入等. 而唯一可以做这些事情的就是操作系统, 所以此时程序就需要先操作系统请求以程序的名义来执行这些操作.
这时需要一个这样的机制: 用户态程序切换到内核态, 但是不能控制在内核态中执行的指令
这种机制叫系统调用, 在CPU中的实现称之为陷阱指令(Trap Instruction)
他们的工作流程如下:
- 用户态程序将一些数据值放在寄存器中, 或者使用参数创建一个堆栈(stack frame), 以此表明需要操作系统提供的服务.
- 用户态程序执行陷阱指令
- CPU切换到内核态, 并跳到位于内存指定位置的指令, 这些指令是操作系统的一部分, 他们具有内存保护, 不可被用户态程序访问
- 这些指令称之为陷阱(trap)或者系统调用处理器(system call handler). 他们会读取程序放入内存的数据参数, 并执行程序请求的服务
- 系统调用完成后, 操作系统会重置CPU为用户态并返回系统调用的结果
当一个任务(进程)执行系统调用而陷入内核代码中执行时,我们就称进程处于内核运行态(或简称为内核态)。此时处理器处于特权级最高的(0级)内核代码中执行。当进程处于内核态时,执行的内核代码会使用当前进程的内核栈。每个进程都有自己的内核栈。当进程在执行用户自己的代码时,则称其处于用户运行态(用户态)。即此时处理器在特权级最低的(3级)用户代码中运行。当正在执行用户程序而突然被中断程序中断时,此时用户程序也可以象征性地称为处于进程的内核态。因为中断处理程序将使用当前进程的内核栈。这与处于内核态的进程的状态有些类似。
内核态与用户态是操作系统的两种运行级别,跟intel cpu没有必然的联系, intel cpu提供Ring0-Ring3三种级别的运行模式,Ring0级别最高,Ring3最低。Linux使用了Ring3级别运行用户态,Ring0作为 内核态,没有使用Ring1和Ring2。Ring3状态不能访问Ring0的地址空间,包括代码和数据。Linux进程的4GB地址空间,3G-4G部 分大家是共享的,是内核态的地址空间,这里存放在整个内核的代码和所有的内核模块,以及内核所维护的数据。用户运行一个程序,该程序所创建的进程开始是运 行在用户态的,如果要执行文件操作,网络数据发送等操作,必须通过write,send等系统调用,这些系统调用会调用内核中的代码来完成操作,这时,必 须切换到Ring0,然后进入3GB-4GB中的内核地址空间去执行这些代码完成操作,完成后,切换回Ring3,回到用户态。这样,用户态的程序就不能 随意操作内核地址空间,具有一定的安全保护作用。
至于说保护模式,是说通过内存页表操作等机制,保证进程间的地址空间不会互相冲突,一个进程的操作不会修改另一个进程的地址空间中的数据。
其实说了这么多,你要了解的大概只有你写的程序,运行是运行在用户态的!但是有时你要进行io,通信,等等 访问外部设备这之类的操作,需要用户态才能进行,于是需要进行用户态与内核态的切换,而这些切换都是要消耗资源的(你连线程切换也需要消耗资源)
以通信为例进行性能比较与原理讲解
普通的通信,先将磁盘信息进行读取,随后在将信息发送出去,下图使其具体的实现
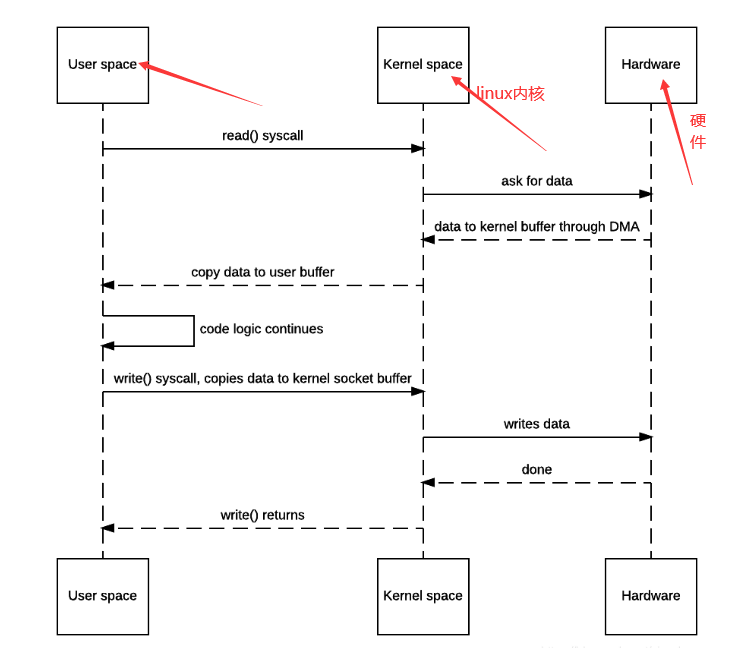
- JVM执行
read()系统调用; - 操作系统从用户态切换到内核态,然后把数据读到内核缓冲区;
- 内核将数据拷贝到应用缓冲区,并切换回用户态,
read()调用返回; - JVM处理代码逻辑,然后执行
write()系统调用; - 操作系统切换到内核态,将数据从应用缓冲区拷贝到socket内核缓冲区;
- 操作系统返回到用户态,JVM继续执行后面的业务逻辑。
一次通信包含了4次用户态内核态切换,3次文件拷贝(将内核缓冲区的数据发送出去时应该不算拷贝)
系统级别的zero-copy
如果有些数据我们不需要进行修改经历上述的4次copy是不是感觉很浪费资源,我们要做的只是将磁盘上的数据发送出去,此时涉及到了zero-copy(linux中通过sendfile()来实现)
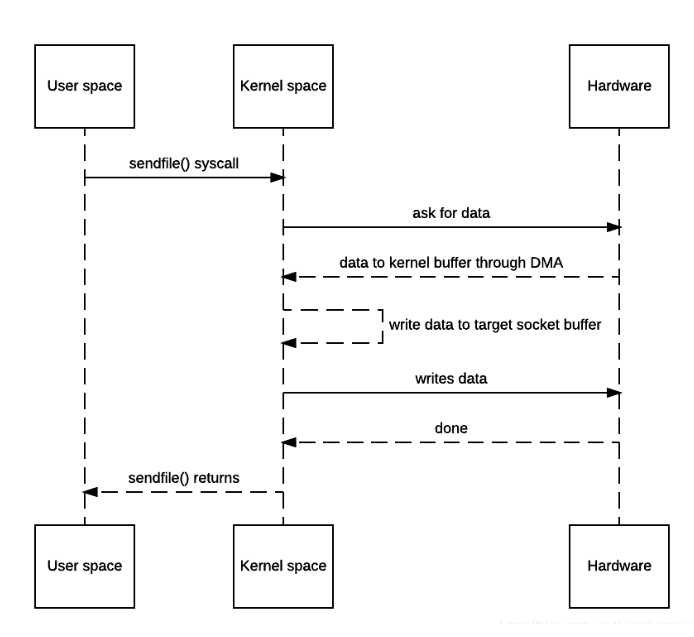
在zero-copy中只需要内核将磁盘信息读取到其内核的缓冲区,随后直接发送出去,此时只涉及到了1次拷贝,与2次上下切换,这2次是不能减少的所以把这个称为zero-copy,但他有一个缺点就是你不能修改其数据在发送出去所以有些适用有些不适用
内存映射mmap
内存映射比zero-copy消耗资源但比传统的要好,就是将磁盘上的那部分空间直接映射(不晓得怎么描述反正内核可以直接访问那一部分区域,不需要先数据拷贝过来才能进行访问)
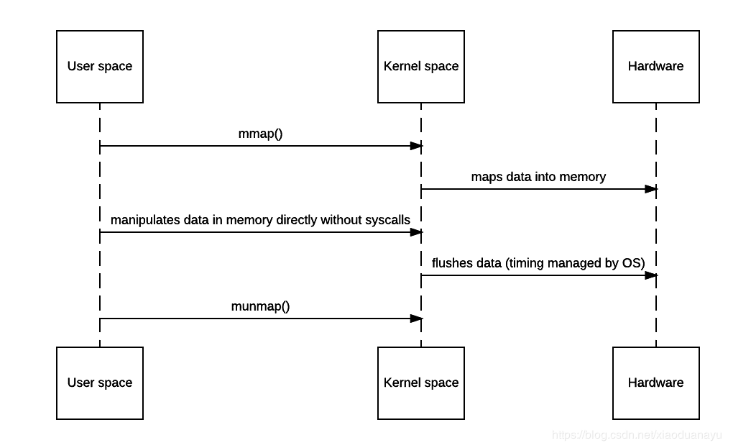
这里仍然需要4次切换,2次数据拷贝(有的说3次),跟zero-copy相比他能改变数据,在epoll,nginx,kafaka都用了这个,在java中也有
Java NIO中有三种ByteBuffer,其api直接使用即可
HeapByteBuffer:ByteBuffer.allocate()使用的就是这种缓冲区,叫堆缓冲区,因为它是在JVM堆内存的,支持GC和缓存优化。但是它不是页对齐的,也就是说如果要使用JNI的方式调用native代码时,JVM会先将它拷贝到页对齐的缓冲空间。DirectByteBuffer:ByteBuffer.allocateDirect()方法被调用时,JVM使用C语言的malloc()方法分配堆外内存。由于不受JVM管理,这个内存空间是页对齐的且不支持GC,和native代码交互频繁时使用这种缓冲区能提高性能。不过内存分配和销毁的事就要靠你自己了。MappedByteBuffer:FileChannel.map()调用返回的就是这种缓冲区,这种缓冲区用的也是堆外内存,本质上其实就是对系统调用mmap()的封装,以便通过代码直接操纵映射物理内存数据。
epoll
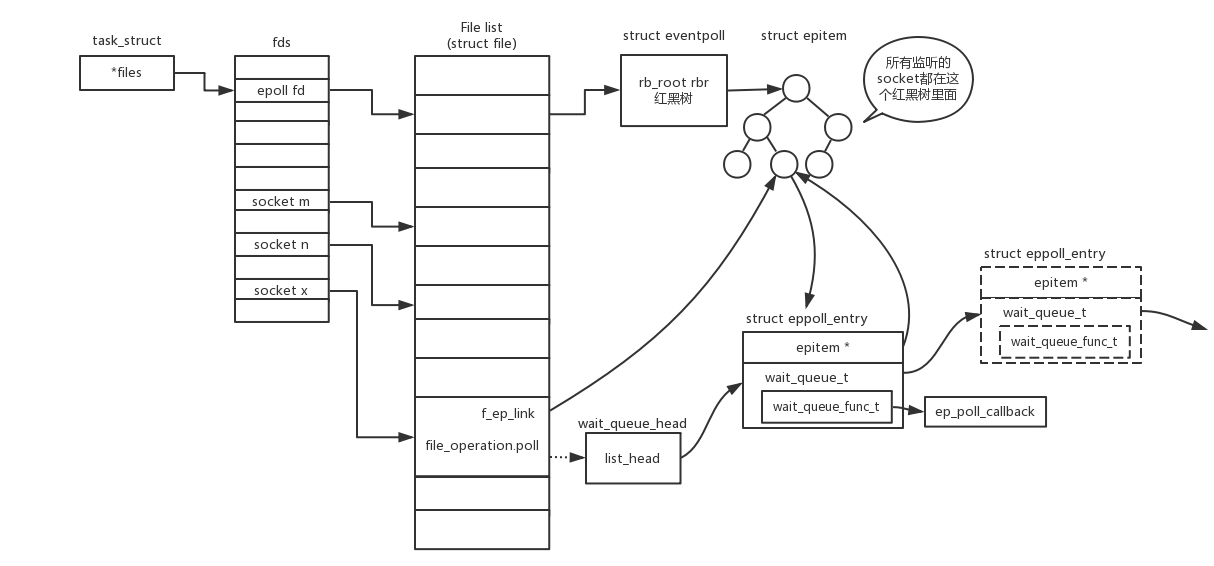
参考文章
http://www.pianshen.com/article/230270085/
https://www.jianshu.com/p/f28eeca6fdae