记录遇到过的问题

在工作中遇到的实际问题
es
es插入太频繁,导致插入越来越慢
页面总是查询不到最近的权重线程池信息,原因排查 kafka消息滞后 ->查看es的健康状态发现cpu过高。
排查结论:es插入太频繁,导致插入速度变慢,es中的数据是通过kafka消费而来,于是页面搜索不到近实时数据
es插入更新原理,refresh,flush,merge
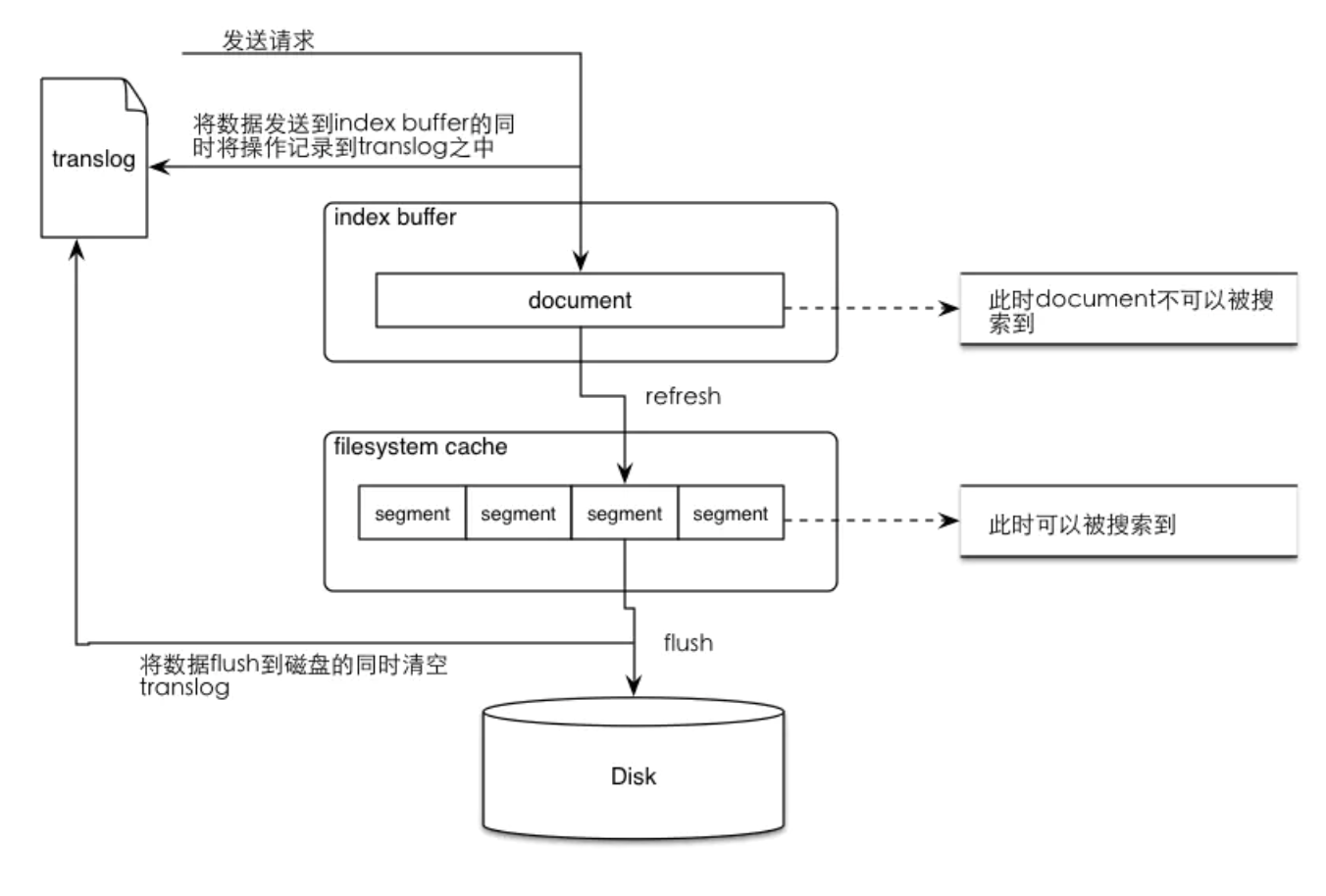
refresh原理
-
数据写入buffer缓冲和translog日志文件中。
当你写一条数据document的时候,一方面写入到mem buffer缓冲中,一方面同时写入到translog日志文件中。 -
buffer满了或者每隔1秒(可配),refresh将mem buffer中的数据生成index segment文件并写入os cache,此时index segment可被打开以供search查询读取,这样文档就可以被搜索到了(注意,此时文档还没有写到磁盘上);然后清空mem buffer供后续使用。可见,refresh实现的是文档从内存移到文件系统缓存的过程。
-
重复上两个步骤,新的segment不断添加到os cache,mem buffer不断被清空,而translog的数据不断增加,随着时间的推移,translog文件会越来越大。
-
当translog长度达到一定程度的时候,会触发flush操作,否则默认每隔30分钟也会定时flush,其主要过程:
4.1. 执行refresh操作将mem buffer中的数据写入到新的segment并写入os cache,然后打开本segment以供search使用,最后再次清空mem buffer。
4.2. 一个commit point被写入磁盘,这个commit point中标明所有的index segment。
4.3. filesystem cache(os cache)中缓存的所有的index segment文件被fsync强制刷到磁盘os disk,当index segment被fsync强制刷到磁盘上以后,就会被打开,供查询使用。
4.4. translog被清空和删除,创建一个新的translog。
由于自动刷新流程(refresh)每秒会创建一个新的段 ,这样会导致短时间内的段数量暴增。而段数目太多会带来较大的麻烦。 每一个段都会消耗文件句柄、内存和cpu运行周期。更重要的是,每个搜索请求都必须轮流检查每个段;所以段越多,搜索也就越慢。
1、 当索引的时候,刷新(refresh)操作会创建新的段并将段打开以供搜索使用。
2、 合并进程选择一小部分大小相似的段,并且在后台将它们合并到更大的段中。这并不会中断索引和搜索。(这一步叫做merge,也十分消耗性能)
elastic.co/guide/cn/elasticsearch/guide/current/merge-process.html
解决方法
不在实时插入,当满100条在插入,这样会减少segment(段)的数量,就会大量降低内存,同样将少了segment,也就减少了merge操作,于是cpu降低。实践证明这样后cpu降低,能查到实时数据
es搜索由于数据量过大,导致搜索过慢
项目监控日志需求,要求记录整个公司已事业部为维度,统计错误日志占比最高的前10,要求有日环比,周同比。
在es中进行以事业部为维度聚合日志总数,错误日志总数,其占比时,写出查询语句发现这一个语句直接超时。
通过缩小时间跨度,发现3个小时内的聚合在5秒以内,于是采用多线程将时间缩短进行分段查询,随后在进行整合,通过堆排序取出前10,将其整体时间控制在15m以内。并每天将所有日志已事业部为维度,存入es中,便于日环比与周同比的计算
es内存熔断
在es中聚合权重线程池中的数据时有一段时间,查询es直接报错,返回Data too large, data for [xxx] would be larger than limit
经过查阅文档发现由于es的内存保护机制导致,当es预估这个查询对内存的消耗超过某个值时,为了防止oom以及影响其他查询,断路器会直接掐断此次查询,并且在一段时间内相同请求不会再生效。
由于内存消耗是按照分配的内存比例而来,于是给es将内存增高就没有再出现。
mysql
查询耗时
一个上千万的文件存储的表,进行分页查询时,发现count(1) 操作都很慢几分钟都无果,但要做到按照时间倒序分页。
实现思路分页是伪分页,没有显示总页数,但你可以自己输入页数以及上一页,下一页。
根据时间倒序排列如果使用order create_time,耗时巨久,用户基本接受不了,但是如果给create_time创建索引,觉得有些不划算,由于id是自增的,且为主键,于是我使用了id进行倒序分页,虽然耗时仍然较高这让用户可以接受此查询时间5s。
session
java
分布式事务中的坑
场景
支付事业部生产环境,突然所有访问超时,机器中一个节点处理不了任何请求,而且对应mysql的机器访问全部超时。瘫痪长达半个小时
排查
每个人员排查自己所负责的组件发现,kafka假死。为何kafka假死会出现这么严重的问题。
排查代码发现代码逻辑大概如下,由于监控需求需要把一些数据发入kafka。于是工作人员在写入数据库之后的事务中,使用了异步线程池,异步线程池做的事就是将数据发送至kafka,异步线程池中所使用的策略为CallerRunsPolicy。
1. AbortPolicy 默认策略,直接跑出异常阻止系统正常运行。
2. CallerRunsPolicy “调用者运行”一种调节机制,该策略既不会抛弃任务,也不会抛出异常,而是将任务回馈至发起方比如main线程。
3. DiscardOldestPolicy 抛弃队列中等待最久的任务,然后把当前任务加入队列中尝试再次提交当前任务。
4. DiscardPolicy 直接丢弃任务,不给予任何处理也不跑出异常,如果允许任务丢失,这是最好的一种方案。
原因分析
- 对于不重要的业务,不建议使用分布式事务
- 此场景中,线程池的策略为CallerRunsPolicy,当kafka阻塞时,线程池拉满,由调用线程来执行,导致tomcat中线程拉满,此节点接受不了任何请求了
- 分布式事务中,开始了mysql的事务但是kafka一直阻塞,导致mysql连接与资源一直被占用且拉满。于是长事务导致mysql资源基本耗尽
总结
分布式中尽量不要使用事务,使用最好带上超时时间,如果不是特别重要的业务线程池不要使用CallerRunsPolicy的拒绝策略。
公司要人背锅时四处踢皮球,声称这是100w买来的教训
oom
线上轩辕平台过2天就行进行一次告警,内存不足,打开日志发现以下问题

显然是gc不了了,思考了一下最近一次上线更新的东西,大概率是redis监控除了问题,为了排查使用了如下命令
# 查看内存使用情况
jmap -heap pid
# 查看内存中前100的大对象
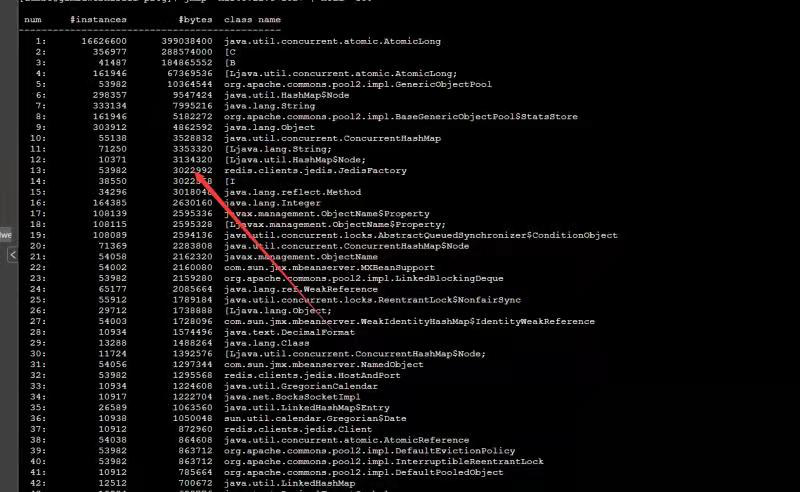
jmap -histo:live pid | head -100
# 生成dump文件
jmap -dump:file=文件名.dump [pid]
用过jmap -histo:live pid | head 100命令观察后发现,2个小时后,jedisFactory涌现了出来,排查代码发现,redis监控对单个jedis进行了关闭,但没有对集群的监控进行关闭,每次定时任务执行后都会创建对象,于是导致一直回收不了出现问题。
线上分析:
下载MAT工具 wget -O mat.zip http://mirrors.neusoft.edu.cn/eclipse/mat/1.10.0/rcp/MemoryAnalyzer-1.10.0.20200225-linux.gtk.x86_64.zip
分析dump文件(hprof)
./mat/ParseHeapDump.sh /tmp/77_17309_ehuser.hprof org.eclipse.mat.api:suspects org.eclipse.mat.api:overview org.eclipse.mat.api:top_components
跳转至/tmp目录,将应用内存dump文件复制到/tmp
下载MAT工具 wget -O mat.zip http://mirrors.neusoft.edu.cn/eclipse/mat/1.10.0/rcp/MemoryAnalyzer-1.10.0.20200225-linux.gtk.x86_64.zip
解压zip
unzip mat.zip
分析dump文件(hprof)
./mat/ParseHeapDump.sh <dump文件名> org.eclipse.mat.api:suspects org.eclipse.mat.api:overview org.eclipse.mat.api:top_components
分析结果为zip文件,与dump文件同目录,下载到本地,解压,打开里面index.html 注:分析大dump文件时,分析过程可能会发生OOM内存溢出,可通过加大mat/MemoryAnalyzer.ini内存参数解决 -Xmx10240m 修改-Xmx的值,使大于hprof文件的大小,建议是其2倍大小