JUC下面的队列

本文来聊一聊JUC下面的并发容器。
JUC下面的并发容器分为三类
- Concurrent
- CopyOnWrite
- Blocking
在此先介绍一下三种的不同之处,随后在讲一讲场景,以及粒度。
Concurrent 类型基于 lock-free,在常见的多线程访问场景,一般可以提供较高吞吐量。我翻看源代码发现除了ConcurrentHashMap,用了一个分段锁外,其他容器均没有使用锁。其替换元素都是通过cas来达到原子性操作。
Blocking 类型都是内部都是基于锁,并且全提供了阻塞调用线程的功能。
CopyOnWrite 在修改或者新增元素时会复制一份数据进行修改。
从命名上可以大概区分为 Concurrent*、CopyOnWrite和 Blocking等三类,同样是线程安全容器,可以简单认为:
- Concurrent 类型没有类似 CopyOnWrite 之类容器相对较重的修改开销。
- 但是,凡事都是有代价的,Concurrent 往往提供了较低的遍历一致性。你可以这样理解所谓的弱一致性,例如,当利用迭代器遍历时,如果容器发生修改,迭代器仍然可以继续进行遍历。
- 与弱一致性对应的,就是我介绍过的同步容器常见的行为“fail-fast”,也就是检测到容器在遍历过程中发生了修改,则抛出 ConcurrentModificationException,不再继续遍历。
- 弱一致性的另外一个体现是,size 等操作准确性是有限的,未必是 100% 准确。
- 与此同时,读取的性能具有一定的不确定性。
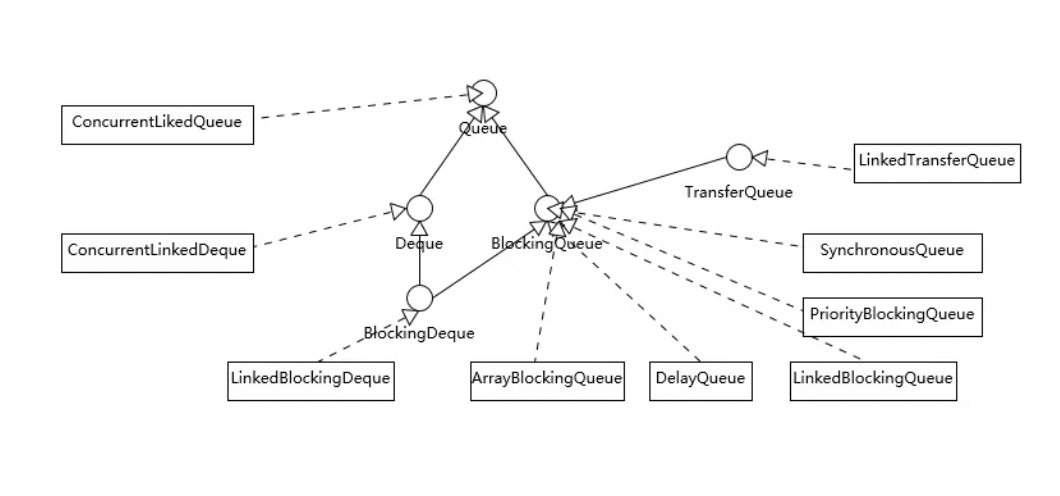
奉上一个继承实现图
分析
Blocking优势
其实个人觉得在生产者消费者模式中使用阻塞队列是比较合适的。当队列里面没有数据时如果还有线程在take,他能帮他阻塞线程,防止cpu空转。
Blocking原理
/** Main lock guarding all access */
final ReentrantLock lock;
/** Condition for waiting takes */
private final Condition notEmpty;
/** Condition for waiting puts */
private final Condition notFull;
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == 0)
notEmpty.await();
return dequeue();
} finally {
lock.unlock();
}
}
/**
* Inserts element at current put position, advances, and signals.
* Call only when holding lock.
*/
private void enqueue(E x) {
// assert lock.getHoldCount() == 1;
// assert items[putIndex] == null;
final Object[] items = this.items;
items[putIndex] = x;
if (++putIndex == items.length)
putIndex = 0;
count++;
notEmpty.signal();
}
如上是ArrayBlockingQueue的源码,其通过一个lock,加这个锁的2个条件变量,在没有数据时将其阻塞,挂起,当有新增元素时将阻塞了的线程进行唤醒。
Blocking阻塞调用者线程的原理就如上所述,再提一嘴LinkedBlockingQueue的锁粒度比ArrayBlockingQueue更细,它使用了2个lock,分别锁住put, offer与take, poll。
Concurrent
Concurrent,他与其他并发容器不同的点在于他遍历时候的一致性,普通容器在原始数据中修改时进行遍历会抛出异常,并不继续遍历,而Concurrent并不会这样所以可以理解为弱一致性。
想必大家好奇的还是ConcurrentHashMap,在此我就讲一下这个分段锁,其实没什么神奇的就是他将锁的粒度细化,锁住的是entry列表,而不是整个hashTable,源码下无秘密
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
// 获取这个key所在的头node
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
//锁住这一个node
synchronized (f) {
···
}
如上图中的中文注释,通过计算hash值,来确实这个key位于哪一个链表/树,随后锁住这一个链表来防止并发问题。
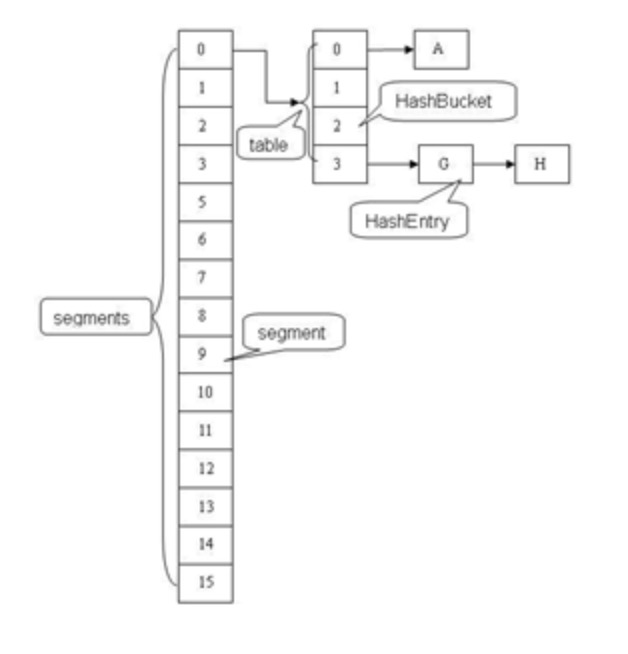
锁住的就是上图中的segment
CopyOnWrite
在更改或者新增的时候,复制一份去进行变动,变动完成后再将引用变成最新的。
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return {@code true} (as specified by {@link Collection#add})
*/
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
相信看了如上代码你就了解了,这种容器并不适合写多读少的场景