迭代器

迭代器用于遍历容器, 迭代器模式将集合对象的遍历操作从集合类中拆分出来,放到迭代器类中,让两者的职责更加单一 ,降低其耦合性。对于链表数组进行遍历你可能觉得使用for循环就比较简单,但对于复杂的数据结构(树,图),自己写代码遍历那可就有点麻烦,所以迭代器模式一定程度上降低了我们遍历的难度。迭代器重要方法next,hasNext
java中的AbstractList
大体上2个重要的内部类Itr,ListItr。在此通过源码解析一下里面的功能,先自己阅读以下留一个印象,后面会讲解
private class Itr implements Iterator<E> {
/**
* Index of element to be returned by subsequent call to next.
*/
int cursor = 0;
/**
* Index of element returned by most recent call to next or
* previous. Reset to -1 if this element is deleted by a call
* to remove.
*/
int lastRet = -1;
/**
* The modCount value that the iterator believes that the backing
* List should have. If this expectation is violated, the iterator
* has detected concurrent modification.
*/
int expectedModCount = modCount;
public boolean hasNext() {
return cursor != size();
}
public E next() {
checkForComodification();
try {
int i = cursor;
E next = get(i);
lastRet = i;
cursor = i + 1;
return next;
} catch (IndexOutOfBoundsException e) {
checkForComodification();
throw new NoSuchElementException();
}
}
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
AbstractList.this.remove(lastRet);
if (lastRet < cursor)
cursor--;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException e) {
throw new ConcurrentModificationException();
}
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
重要元素
cursor 当前元素的位置,lastRet最近一个访问元素的位置,当他为-1时证明最近访问一个元素已被移除。expectedModCount期望的modCount,modCount是ArrayList中记录数组改变的次数。
为什么要重点提一下这几个元素
1.迭代器中当你删除和添加元素后,往往会导致遍历的时候回漏掉元素,这样就导致遍历的不准,于是你应该遇到过ConcurrentModificationException(),这就是当你在遍历元素时,容器元素被改变。添加元素有概率会重复遍历一个元素(当你加在他遍历之前时,游标指向了他之前遍历过的元素),删除元素时会漏掉元素(删掉了遍历过的元素,导致游标指向了下一个未遍历的元素)
2.为了保证遍历的准确性,杜绝掉这种结果不可预期行为或者未决行为 (就是又可能删除元素后访问可能有问题,可能没问题), 通常有2中方法,一种是遍历的时候不允许增删元素,另一种是增删元素之后让遍历报错 。由于第一种实现较难你不晓得何时会遍历完成。于是通过在遍历过程中是不允许增加或者删除元素。至于如何实现就需要前面提到过的几个元素。
源码中的checkForComodification() 方法用于比较是否容器中的元素有变换,若有则抛出异常。细心的可能会发现他也提供了remove()方法,它能够删除即将遍历的下一个元素,但不能连续删除,否则抛出IllegalStateException(),不清楚请仔细看源码
AbstractList.this.xxxx,表示调用AbstractList类的xxxx方法或者元素,而不是本类的方法或者元素
LinkList的迭代器
方法是一样的遵循迭代器的方法,只不过用Node来代替序列,增加了迭代器中add,remove方法可以在遍历时自由通过此迭代器增加或者删除元素,记住是使用迭代器的add,因为LinkList的add方法没有增加expectedModCount的值
private Node<E> lastReturned;
private Node<E> next;
private int nextIndex;
private int expectedModCount = modCount;
public E next() {
checkForComodification();
if (!hasNext())
throw new NoSuchElementException();
lastReturned = next;
next = next.next;
nextIndex++;
return lastReturned.item;
}
public void add(E e) {
checkForComodification();
lastReturned = null;
if (next == null)
linkLast(e);
else
linkBefore(e, next);
nextIndex++;
expectedModCount++;
}
public void remove() {
checkForComodification();
if (lastReturned == null)
throw new IllegalStateException();
Node<E> lastNext = lastReturned.next;
unlink(lastReturned);
if (next == lastReturned)
next = lastNext;
else
nextIndex--;
lastReturned = null;
expectedModCount++;
}
个人觉得在linkList遍历过程中删除元素,不会造成重复读,或者漏读,但是如果在遍历过程不是通过迭代器修改了他还是会抛出ConcurrentModificationException,相比ArrayList,他能够用迭代器一直加元素了。
HashMap
hashMap的迭代器一个重要类HashIterator,更具map的遍历方式你应该也能想到他会有一个迭代器 KeyIterator,ValueIterator,EntryIterator。其遍历的方式是根据其数据结构决定桶加链表(红黑树)。源码之下无密码我们来瞧一瞧吧
abstract class HashIterator {
Node<K,V> next; // next entry to return
Node<K,V> current; // current entry
int expectedModCount; // for fast-fail
int index; // current slot
HashIterator() {
expectedModCount = modCount;
Node<K,V>[] t = table;
current = next = null;
index = 0;
if (t != null && size > 0) { // advance to first entry
do {} while (index < t.length && (next = t[index++]) == null);
}
}
public final boolean hasNext() {
return next != null;
}
final Node<K,V> nextNode() {
Node<K,V>[] t;
Node<K,V> e = next;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
if ((next = (current = e).next) == null && (t = table) != null) {
do {} while (index < t.length && (next = t[index++]) == null);
}
return e;
}
public final void remove() {
Node<K,V> p = current;
if (p == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
current = null;
K key = p.key;
removeNode(hash(key), key, null, false, false);
expectedModCount = modCount;
}
}
在此点一下里面的一些代码吧,毕竟源码还是要自己读才有意思,能体会其牛逼。index指的是他在哪个slot(桶),nextNode()方法中的
(next = (current = e).next) == null ,这一部分每次来都会执行,他每次都会将next指向下一个元素,而e一直都是当前的元素。当这个表达式为空时时证明这个链表已经到末尾了下一个元素需要进入下一个桶,于是next = t[index++],next成功指向下一个,而e一直指向的是现在应该指向的元素。
这个抽象类的子类KeyIterator,ValueIterator,EntryIterator,你看了源码你就会晓得其实你的foreach,遍历的优越。
final class KeyIterator extends HashIterator
implements Iterator<K> {
public final K next() { return nextNode().key; }
}
final class ValueIterator extends HashIterator
implements Iterator<V> {
public final V next() { return nextNode().value; }
}
final class EntryIterator extends HashIterator
implements Iterator<Map.Entry<K,V>> {
public final Map.Entry<K,V> next() { return nextNode(); }
}
KeyIterator就是取里面的key,ValueIterator就是取value值,于是我建议,当你在遍历中需要用到value和key的时候直接用entry吧。不要在通过啥子KeyIterator遍历到key后,再map.get(key)。好像一直忘记说了foreach只是迭代器的语法糖。你可以反编译进行查看。 javap -c 反编译如下如
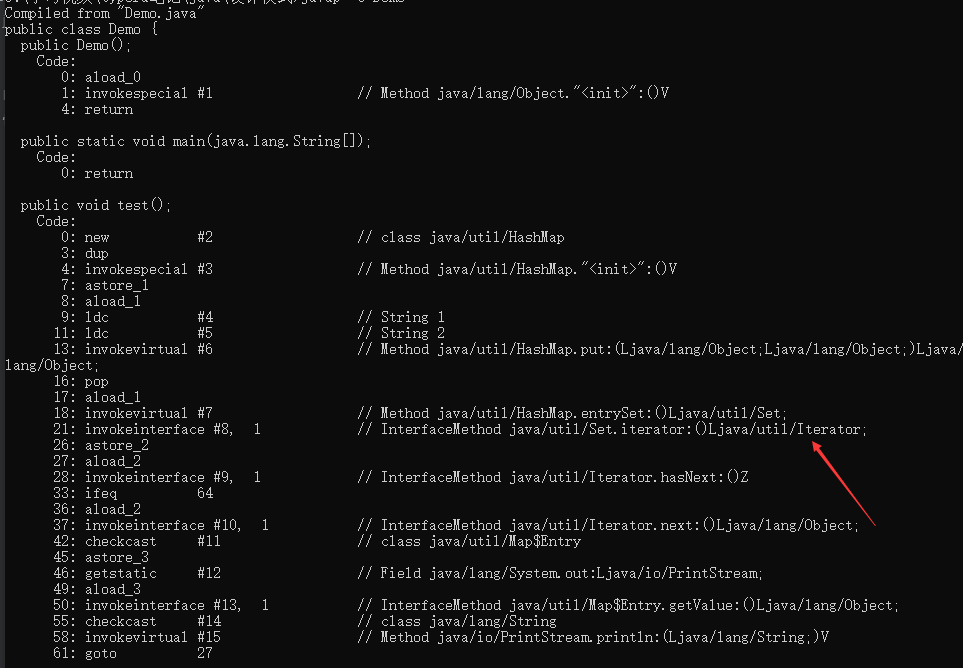
快照
前面提到过,在遍历时由于他读的是原数组,于是导致其他线程对此数组的增删操作会抛出ConcurrentModificationException,可以你会想我们是不是可以在使用迭代器的时候构建一个快照snap。在此我就分析分析我对这里构建快照的几种方法与其看法。
1.你可以在构建直接迭代器的时候直接拷贝原数组,在此浅拷贝就行,内存的额外增加不会过大。实现较为简单,但是有多少个迭代器就会增加多少个容器引用的大小,如果同时迭代的过多,内存占有还是很大
2.是不是联想到了mysql的事务,来我们仿照MVCC模式
2.1 对容器中的每一个对象加时间,即新增时间,删除时间。所有的增加删除都带有时间并且删除数据逻辑删除,即增加一个删除标记。
2.2 在容器中增加一个链表,链表记录每个迭代器,并带有其创建时间,是否已经遍历完成
2.3 迭代器遍历的时候对比容器中的数据的时间,达到隔离性,即在此迭代器创建之前已经删除的不可见,在此迭代器创建之后新增的,不可见。迭代完成后从链表中删除
2.4 随后就是将以后不可能再访问的数据删除。即所有迭代器的创造时间都在其后面则这个元素以后永远也用不到可以进行真正的删除。因为在容器中用了一个链表按顺序保存,于是可以将删除的元素的时间更链表第一个迭代器(前提他已经遍历完了)比较如果时间小于此迭代器创建时间,则此元素可以删除,因为每次都要遍历比较个人觉得耗时蹩脚。
2.5 可能你会觉得这个删除不怎么优雅,我也这么觉得,于是再思考思考。想要快索引肯定少不了,从索引出发进行思考,空间换时间!......... 思考良久后想了一个蹩脚的办法。在容器中增加保存删除元素的容器(链表还是数组自己衡量)命名为软删除容器,每个迭代器创建的时候将此容器中的数据浅拷贝一份到自己的地方,随后一个迭代器迭代完就查看迭代器链表的第一个是否已经迭代完,如果迭代完就删除掉里面的容器里逻辑删除元素,随后在软删除容器中也删除掉那些引用。
最后提一句:想了这么多 还是直接抛个异常简单明了